
Ve hrách jako piškvorky, dáma a šachy postupně počítače dosáhly lepších výsledků, než lidští soupeři. Ale prastará čínská hra go odolávala umělé inteligenci více, než zdařile. Předpokládalo se, že bude trvat minimálně deset let, než nejlepší počítače začnou v zdánlivě jednoduché hře porážet mistry. „A myslím si, že i těch deset let je moc optimistických,“ řekl v roce 2014 programátor Remi Coulom, který vyvinul jeden z dosud nejlepších programů hrajících go. Dnes Coulom přiznává, že jej tento zvrat zaskočil: „Došlo k tomu rychleji, než jsem čekal.“
Jak funguje AlphaGo |


Lidský soupeř, evropský šampion Fan Hui, kterého umělá inteligence s přehledem pětkrát porazila (i když Hui vyhrál dva z pěti přípravných zápasů), byl výsledkem rovněž překvapen: „V Číně není go jen hra, je to odraz života. Byla to těžká porážka. Čekal jsem totiž, že vyhraju. Po první hře jsem změnil strategii a hrál jsem agresivněji, ale stejně jsem prohrál.“ Domnívá se, že to je obecný problém lidí: „Někdy jsme unavení, někdy toužíme po vítězství a necháme se unést. Počítačový program tyto tlaky nemá. Je silný a stabilní. Bylo to jako hrát proti zdi.“
Pravidla GoGo je hra s relativně jednoduchými pravidly, ve které náhoda nehraje žádnou roli. Hrací deska má rozměr 19×19 políček (ve skutečnosti průsečíku linií na ploše, ale to je vlastně jedno). Hráči mají kameny různé barvy, které střídavě mohou klást na libovolné volné hrací pole. Vždy začíná černý, a hráči se snaží zcela obklíčit soupeřovy kameny a zabránit mu v obklíčení svých vlastních. Hra končí ve chvíli, když se oba hráči vzdají tahu, a vyhrává zjednodušeně řečeno ten, kdo ovládne větší území (ve skutečnost je to složitější a skóre se může počítat různými způsoby podle různých pravidel). Hráči Go se tedy snaží vytvořit souvislé bloky ze svých kamenů a zabránit v tomtéž soupeři. Zdá se to jednoduché, pro počítačovou analýzu je ale hra go nesmírně obtížná svým rozsahem. |
Hrubou silou se s dnešní technologií hra go vyřešit nedá. Na začátku hry je k dispozici 361 možností, jak zahrát a po pěti kolech může být hrací plocha uspořádána do celkem zhruba pět bilionů (5×1012) možných konfigurací. Pro srovnání, šachovnice může po deseti tazích (po pěti každého hráče) uspořádána „jen“ necelými pěti miliony způsobů. Rozdíl tří řádů se pak rychle zvětšuje, a v go je celkem k dispozici více než 10170 různých konfigurací kamenů na desce. To je o mnoho řádů více možností, než kolik by dnešní počítače mohly v nějaké smysluplné době projít.
Pro extrémně velké množství kombinací je go považováno počítačovými výzkumníky za nesmírně obtížný problém. Snaha počítat všechny varianty (jako například u piškvorek nebo u dámy) zde totiž nepřipadá v úvahu.
Slibně vypadaly algoritmy, které umožňují zúžit výběr místa pro optimální položení kamene. Postupně se pak podařilo vytvořit programy, které dokázaly s poměrně velkou pravděpodobností předpovědět, kam zkušený lidský hráč pokládá své kameny. Přesnost jejich předpovědi nebyla ohromující, trefili se ve zhruba 40 procentech případů.
Tým Googlu (původně z londýnské firmy DeepMind, kterou Google před dvěma lety koupil) tuto přesnost vylepšil na zhruba 55 procent. Důležitější ale byla kombinace této „konvoluční sítě“ se „stromovým prohledáváním“, které skloubil software nazvaný AlphaGo.

Seznam všech her (oficiálních i neoficiálních) mezi Fan Hui a AlphaGo
Nápodobou směle vpřed
Hlavním nástrojem vývojářů byly tzv. hluboké neuronové sítě. Neuronové sítě jsou systémy umělé inteligence založené na principech odkoukaných od mozku. Tvoří je celá řada „neuronů“ propojených za sebou i mezi sebou, které se (hodně zjednodušeně řečeno) postupně samy i s pomocí programátorů učí ze vstupních dat dojít ke správnému výsledku. Postupně se tak „ladí“, trénují a vylepšují, a dokáží tak dnes běžně zvládat úkoly, které jiným typů algoritmů dělaly velké problémy: třeba rozpoznávání obličejů atp. Hluboké neuronové sítě se od běžných neuronových sítí liší hlavně tím, že mají více vrstev. V případě AlphaGo běží výpočet ve 13 vrstvách nad sebou najednou.

Trénování neuronových sítí probíhá v několika vrstvách a vychází jak ze skutečných zápasů, tak ze simulovaných výsledků. Počítač tak získá pravděpodobnostní mapu herního pole, ze které vybírá možné tahy.
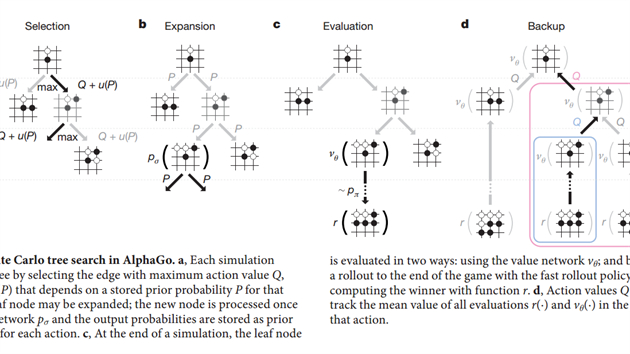
Umělá inteligence AlphaGoHluboké neuronové sítě se učí z dodaných dat, v tomto případě z již odehraných profesionálních partií i z her, které hraje AlphaGo sama proti sobě. Sítě dávají tipy na vhodné tahy, případně říkají, která pozice vypadá jako vyhraná a která jako prohraná. Napodobují lidskou intuici. Prohledávání stromu (Monte Carlo Tree Search) je statistická metoda, pomocí které hledá umělá inteligence nejlepší tahy na základě toho, jak by hra mohla skončit. Prohledávání stromu vzdáleně odpovídá tomu, když si člověk v hlavě představuje průběh partie několik tahů dopředu. |
Software Googlu je složen z kombinace neuronových sítí a prohledávání stromu možných tahů. Jsou zde dvě hlavní neuronové sítě, každá má jinou úlohu. První bychom mohli nazvat jako „strategickou“ (autoři ji nazvali policy network), protože provádí jakýsi předvýběr vhodných vhodných možností pro další tah (viz výše). Druhá je síť „hodnotící“ (value network) a hodnotí pozice jako dobré nebo špatné. „Tím snižuje hloubku prohledávaného stromu,“ vysvětluje Josef Moudřík, doktorand na MFF UK a člen České asociace go.
Neuronové sítě zúží výběr natolik, aby druhá část AlphaGo - stromové prohledávání - mohla vybrat optimální možnost právě z těch předvybraných. Nemusí tak propočítávat ověřovat stovky možných tahů, ale třeba jen čtyři neuronovou sítí nejdoporučovanější. Právě tato kombinace posunula AlphaGo na špičku současných počítačových hráčů go. „Navíc to mají dobře naprogramováno, takže se jim daří zvyšovat výkon přidáváním hardware, což není samozřejmé,“ připomíná Moudřík. „Při distribuované hře tak AlphaGo běží na 1200 procesorech a 180 grafických kartách, což je bezprecedentní.“
V březnu by se měl program AlphaGo utkat se zřejmě nejlepším hráčem moderní doby, Korejcem Lee Sedolem. Sedol je hvězda go, zdaleka nejúspěšnější hráč minulé dekády a Fan Huie překonává o třídu.
Ale počítač rozhodně není bez šance. I proto, že do března se toho nejspíše jeho hodně naučí. Od listopadu, kdy se hrály partie s Huiem, uplyne pět měsíců. Neuronové sítě se stejně jako lidský mozek učí opakováním, ale byť se učí obvykle pomaleji, samotné opakování jim jde o hodně rychleji. Za hodinu odehrají tisíce partií, a z každé něco (málo) pochytí. Uvidíme, jestli to na lidského šampióna bude stačit.
Čím bylo vítězství AlphaGo neobvyklé?Význam pro Technet.cz okomentoval Josef Moudřík, výzkumník v oblasti umělé inteligence na MFF UK a amatérský hráč go. Jak dlouho musí člověk hrát go, aby dokázal porazit algoritmy (vyjma toho AlphaGo)? Předchozí nejsilnější programy (CrazyStone, Zen, DolBaram) byly téměř na úrovni nejsilnějších amatérských hráčů, v systému hodnocení přibližně měly 5dan. Aby se amatér dostal na tuto úroveň musí Go hrát poměrně dlouho, hodně studovat a ani tak se to nepodaří každému kdo se o to pokusí. Samozřejmě existují nadaní lidé, kteří se na tuto úroveň dostanou za několik málo let, ale ti jsou většinou velkou výjimkou. Ovšem rozdíl mezi 5 danem a profesionálním hráčem, jako je Fan Hui, je velký - zhruba handikepové 2-3 kameny (náskok 2-3 tahů na začátku hry; ten dostane slabší hráč aby se vyrovnaly šance na výhru). Obdobně, rozdíl mezi Fan Huiem a špičkou v Go (jako je např. Lee Sedol) je také velmi zhruba 2 kameny. Máme před sebou velmi zajímavé zápasy. Byla hra počítače v něčem zajímavá? Oba hráči jsou ale mnohem silnější než já, takže si netroufnu hodnotit, jaký tah byla či nebyla chyba. Faktem ale je, že AlphaGo předvedl velmi stabilní a dobré schopnosti v boji, a Fan Huie jasně přehrál. (Hodnocení partie profesionálním hráčem najdete třeba zde, pozn. red.) Lze tyto principy AI využít i jinde? Nebo je to natolik specifická aplikace, že má použití jen v go? Algoritmy použité v AlphaGo jsou velmi obecné, na rozdíl od programů pro šachy neobsahují téměř žádnou předem danou (lidmi naprogramovanou) doménovou znalost; tu se algoritmy učí samy zcela samy, v případě AlphaGo jak ze záznamů profesionálních her, tak sebezdokonalováním, kdy program hraje sám proti sobě. Automatické učení znalostí je velmi výhodné (a obtížné), protože v doménách - jako je go - není vůbec není jasné, jak principy "silné hry" formálně vyjádřit. Tradiční metoda ručně naprogramovaných znalostí vede ke spoustě chyb a úmorné práci při vylaďování nejlepší kombinace parametrů. To vše odpadá, když se algoritmus znalosti učí sám - v tomto případě jsou znalosti zakódované do vah neuronové sítě. |


