Úvod
Není jistě žádnou novinkou, že jsou nové procesory svojí architekturou velmi komplikované. Možná se vám bude zdát, že ty staré byly jednoduché, ale tak tomu bohužel není a nebylo.
Tento článek si klade za cíl přiblížit čtenáři architekturu procesoru a některé její zvláštnosti, které přicházejí s novou generací procesorů Pentium, s generací Pentia 4. K dalším technologiím se (doufejme) vrátíme později, v dalších článcích.
Hyper-Pipelined Technology
Objektivní a hlavně kompletní analýzu procesoru asi nejsme schopni udělat, neboť nemáme možnost dostat se ke všem potřebným informacím. Ty mají k dispozici nejspíše pouze pracovnící laboratoří společností, jako je Intel, AMD, Motorola a jiné, a ty tyto informace pečlivě střeží.
I přes tato fakta si z několika informací, které jsou dostupné, můžeme udělat obrázek o tom, jak s největší pravděpodobností i ten nejmodernější procesor pracuje.
Něco málo základních informací
Předně je třeba konstatovat, že vnitřní design procesoru se nazývá "mikroarchitektura" a že každý výrobce procesorů používá rozdílné technologie, různé způsoby a triky, jak ze svého designu (návrhu mikroarchitektury), vytěžit co nejvíce.
Díky tomu prakticky nenajdeme na trhu identické procesory od dvou různých výrobců, protože se každý snaží z určitých základních principů vytěžit ono maximum - a to zcela jiným způsobem návrhu příslušných obvodů. Tím maximem je potom myšleno: co největší výkon, co největší rychlost a co nejnižší cenu. (Například hledat nějakou paralelu mezi procesory AMD Athlon XP a Intel Pentium 4, je jako hledat jehlu v kupce sena - oba procesory jsou velmi rozdílné).
A aby to nebylo už vůbec jednoduché, tak do toho všeho ještě vstupují marketingová oddělení jednotlivých firem. Ta příslušné mikroarchitektuře dělají reklamu a snaží se jí jakýmkoliv způsobem zviditelnit a trumfnout tak konkurenci. To znamená, že zdůrazňují to, co je nepodstatné, objevují dávno objevené, starým věcem dávají nová, ještě šílenější jména a tak podobně. Zkrátka a dobře, lobují za svůj výrobek všemi možnými prostředky. To nám pochopitelně při jakékoliv analýze stěžuje situaci.
Jak z procesoru vyždímat největší výkon
Než se přímo podíváme na jeden z posledních procesorů od Intelu, je třeba zopakovat základní informace tak, aby byl i běžný čtenář schopen pochopit o co jde.
Čili, prozatím jsou známé tři (nebo chcete-li dvě) základní možnosti, jak zvýšit výkon procesoru a to:
- zvýšením vnitřního paralelismu procesoru
- efektivnějším cacheovaním
- zvýšením pracovní frekvence
(poznámka: samozřejmě existují i další možnosti, ale těm se prozatím věnovat nebudeme.)
Procesor je zařízení (jednotka) zpracovávající instrukce. Každá instrukce procesoru je naprogramována pomocí mikrokódu (mikroprogramu) a zvýšení efektivity mikrokódu znamená, že čip využívá lépe každý hodinový cyklus, lépe využívá svojí pracovní frekvenci (nejčastěji udávanou v MHz nebo GHz).
To se odrazí na tom, kolik je schopen procesor zpracovat instrukcí během jednoho cyklu, tj. IPC (Instruction Per Cycle). Čím je počet IPC větší, tím je procesor výkonnější. (Tedy alespoň teoreticky.)
Teoreticky je možné, aby každá instrukce (nebo aby více instrukcí) byla provedená během jednoho taktu. V takovém případě se jedná o zřetězené zpracování instrukcí, neboli pipelining.
Klasické zpracování instrukcí:
- Krok 1: Instruction Access (IA) -- Jde o vstup instrukce, kdy je kódovaná instrukce načtená z
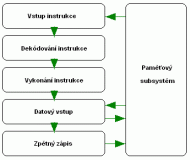 paměťového subsystému (z Cache, z RAM atd.)
paměťového subsystému (z Cache, z RAM atd.) - Krok 2: Instruction Decode (ID) -- Dekódování instrukce. Kódovaná instrukce je přeložena do kontrolní informace pro logické obvody procesoru. Například se určí její typ, délka, zjistí se jestli neobsahuje data, která mají být okamžitě/přednostně zpracována atd.
- Krok 3: Execution (EX) -- Vlastní vykonání instrukce/provedení instrukce. Může se jednat o sčítání, násobení, dělení, nebo se může jednat jen o přesun dat.
- Krok 4: Data Access (DA) -- V této části instrukce mohou být požadována dodatečná data z paměťového subsystému - vyšle požadavek a obdrží zpátky data.
- Krok 5: Store (Write back) Results (WB) - Ihned jakmile procesor vykoná příslušnou instrukci, zapíše výsledek, nebo počká na dokončení.

Tabulka klasického zpracování instrukcí
| T01 | T02 | T03 | T04 | T05 | T06 | T07 | T08 | T09 | T10 | T11 | T12 | T13 | T14 | T15 | |
| IA | I1 | I2 | I3 | ||||||||||||
| ID | I1 | I2 | I3 | ||||||||||||
| EX | I1 | I2 | I3 | ||||||||||||
| DA | I1 | I2 | I3 | ||||||||||||
| WB | I1 | I2 | I3 |
V prvním řádku tabulky jsou zaneseny jednotlivé takty (takt první = T01, takt druhý = T02 atd... takt patnáctý = T15). V prvním sloupečku tabulky jsou pak zaneseny jednotlivé kroky zpracování instrukce (IA = čtení, ID = dekódování atd.). Při klasickém zpracování instrukcí vše probíhá tak, že taktu číslo 01 procesor provede čtení instrukce, ve druhém taktu instrukci dekóduje, ve třetím provede a tak postupuje dál, až pátým taktem instrukci dokončí. V šestém taktu se pak započne instrukce nová.
Při klasickém zpracování instrukcí a pětistupňové pipeline se provedou během 15ti taktů pouze 3 instrukce. Díky tomu procesor pracuje značně neefektivně.
Tabulka zřetězeného zpracování instrukcí
| T01 | T02 | T03 | T04 | T05 | T06 | T07 | T08 | T09 | T10 | T11 | T12 | T13 | T14 | T15 | |
| IA | I01 | I02 | I03 | I04 | I05 | I06 | I07 | I08 | I09 | I10 | I11 | I12 | I13 | I14 | I15 |
| ID | I01 | I02 | I03 | I04 | I05 | I06 | I07 | I08 | I09 | I10 | I11 | I12 | I13 | I14 | |
| EX | I01 | I02 | I03 | I04 | I05 | I06 | I07 | I08 | I09 | I10 | I11 | I12 | I13 | ||
| DA | I01 | I02 | I03 | I04 | I05 | I06 | I07 | I08 | I09 | I10 | I11 | I12 | |||
| WB | I01 | I02 | I03 | I04 | I05 | I06 | I07 | I08 | I09 | I10 | I11 |
Při zřetězeném zpracování instrukce už je to o něčem jiném. Při prvním taktu opět proběhne čtení první instrukce jako v předešlém případě a stejně tak jako v předešlém případě se po pěti taktech celá první instrukce dokončí. Ovšem mezitím co probíhalo zpracování první instrukce, začalo počínaje druhým taktem zpracování druhé instrukce. Díky tomu je každý následující takt po pátém taktu dokončena vždy jedna instrukce. V ideálním případě je tak po patnácti taktech úplně zpracováno 11 instrukcí a další jsou rozpracovány.
Pipeline Pentia 4
Při honbě za maximálním výkonem se tedy postup inženýrů zdá být jasný - co nejkratší pipeline a co nejvíce IPC. Ale.
Ve světě x86 32-bitových procesorů platí, že čím je u procesoru kratší pipeline, tím je procesor schopen sice dosahovat většího množství IPC, ale za cenu podstatně nižších frekvencí, na kterých je poté schopen pracovat. Proč? Od určitého okamžiku totiž nejsou komplikované obvody vykonávající jednotlivé kroky zpracování instrukce schopny dokončit prácí v požadovaném časovém úseku. A to je velký problém.
Proto se v moderních procesorech jakým je například Pentium 4 celý proces pěti základních operací s instrukcí rozkládá na větší počet postupných, (zdánlivě) jednodušších kroků. A právě díky tomu mohou tyto procesory dosahovat velmi vysokých frekvencí.
Pipeline P4 krok za krokem
![]()
Krok 1 a 2: Trace Cache next Instruction Pointer -- V těchto dvou krocích probíhá čtení informací o uložených instrukcích v Trace Cache.
Krok 3 a 4: Trace Cache Fetch -- Další dva kroky sloužící ke čtení instrukce z velmi rychlé Trace Cache. Budou dál poslány do jednotky, která nakonec instrukci vykoná.
Krok 5: Drive -- Drive krok je naprosto unikátní. Nevím o tom, že by se něco podobného vyskytovalo u jiného procesoru. Je to první ze dvou "Drive" kroků v pipeline pentia 4. Jsou určeny k řízení signálů z jedné části procesoru do jiné. Pentium 4 běží tak rychle, že některé signály nemůžou použít všechny cesty k tomu, aby se dostaly na správné místo ve správný čas. A aby nedošlo k chybě a nemusela se celá pipeline zbytečně vymazat, vyhradí procesor tento krok k posílání těchto signálů čipem.
Kroky 6 až 8: Allocate and Rename -- Alokace a přejmenování: Tato skupina kroků manipuluje alokací mikroarchitekturálních zdrojů registrů. Přejmenování je vlastně trik k předcházení konfliktů v případě, že je v mikroarchitektuře více registrů, než je ve specifikaci ISA (instruction set architecture). Tyto extra mikroarchitekturální registry (P4 jich ma 128) jsou alokovány a připraveny v tomto kroku k použití.
Krok 9: Queue -- Fronta: Ve skutečnosti jsou zde dvě fronty mezi Alokátorem/přejmenovávačem a mezi logickým časovačem. Jedna paměťová mikro op fronta a jedna aritmetická fronta. Tyto fronty jsou vlastně místem, kde mikro ops čekají před tím, než budou odeslány ven do jednoho ze čtyřech odbavovacích portů.
Krok 10 až 12: Schedule -- Plánovač určuje, kdy je instrukce připravena na to, aby byla vykonána a zároveň dovoluje to, aby byly instrukce přeuspořádány.
Kroky 13 a 14: Dispatch -- V těchto dvou krocích instrukce putuje skrz jeden ze čtyřech odbavovacích portů k vykonání
Kroky 15 a 16: Register Files -- Po překonání odbavovacích portů v posledních dvou krocích je instrukce nahrána do registrů.
Krok 17: Execute -- V tomto kroku je instrukce konečně vykonána.
Krok 18: Flags -- Pokud je to potřeba, přiřadí se v tomto kroku signalizační bit. (Jinak prakticky nepodstatná část.)
Krok 19: Branch Check -- "Kontrola větvení" je místem, kde si P4 ověřuje výsledek a porovnává správnost s předpovědí.
Krok 20: Drive -- viz krok 5
Poznámka na závěr
Dlouhá Pipeline má kromě svých výhod, i řadu nevýhod. Je třeba značně závislá na optimalizaci software. Ostatně optimalizace softwaru na evolučně starší procesory jako je například Intel Pentium III má za následek u, v uvozovkách nízkotaktovaných, procesorů třídy Intel Pentium 4 zbytečné ztráty výkonu. Dovolil bych si dokonce tvrdit, že rozdíl mezi (ne)srovnatelnými procesory od AMD způsobuje právě optimalizace softwaru, ke které Intel tentokrát přistoupil, zdá se, macešským způsobem.
Ztráty výkonu nastávají vždy v momentě, kdy nějaká instrukce způsobí chybu, nebo neočekávaný skok stejně tak, jako když jsou náhle požadována data z paměti "mimo" pořadí. V takovém případě se za normálních okolností musí všechny probíhající instrukce ukončit, pipeline vyprázdnit a následně znovu zaplnit.
O Pentiu 4 se toho už napsalo hodně, ale málo se ví, že tento procesor využívá (odpusťtě mi ten výraz) naprosto neskutečných triků k tomu, aby svojí pipeline vyprazdňovat nemuselo. Dokáže vykonávat instrukce mimo pořadí a dokonce je dokáže pozastavovat. O tom si ale, jak jsem se již v úvodu zmínil, povíme někdy příště.


