
Jak funguje vyhledávání textových dokumentů a webových stránek je myslím každému jasné. Každý takový dokument je opatřen popisnými daty, kterým se odborně říká metadata a jsou v nich uvedeny podstatné informace o dokumentu. Název, autor, datum publikování ... a klíčová slova. Díky nim stačí do vyhledávače zadat jedno slovo a jako odpověď dostanete spoustu textů, ve kterých se daný výraz vyskytuje.
Jenže jak hledat video, které neobsahuje žádná slova, žádné texty? Podle čeho lze takovéto video - dokumenty vyhledávat? Smyslem tohoto textu je ukázat na několika konkrétních příkladech různá řešení zpracování, roztřídění a především prezentace videa v prostředí internetu.
Zatím jen textově
Možnosti prohledávání a organizace videa jsou potenciálně velmi široké. Můžeme používat takové pokročilé technologie, jako je rozpoznávání obrazu nebo zvuku, konkrétních sekvencí, slov nebo jejich fragmentů.
Ačkoliv na cestě k těmto možnostem ještě stojí řada problémů a překážek (například nevalná kvalita obrazových a zvukových podkladů, rychlost a nákladnost takového zpracování), zdá se, že je pouze otázkou času, kdy budeme video hledat daleko sofistikovaněji než pomocí obyčejného slovního popisu, jako je tomu nyní.
Ambicí tohoto článku tedy není podat vyčerpávající přehled o všech dostupných internetových zdrojích, nástrojích a službách, které nabízejí vyhledávání videa, a rovněž vynechává oblast placených služeb. Zcela vynecháváme i oblast serverů a jejich vyhledávacích nástrojů specializovaných na filmy a problematiku sítí P2P, kterým byl věnován samostatný článek. Tolik varování na úvod ;-).
Co víme a zároveň zapomínáme o videu na internetu?
Máme-li se zabývat vyhledáváním videa dostupného v síti internet, připomeňme na úvod jednu samozřejmost, která bude důležitá pro pochopení inovativnosti popsaných principů. A to fakt, že video sice není text nebo webová stránka, ale má také svoji vnitřní strukturu a lze jej popsat pomocí metajazyka. Stejně jako texty či webové stránky ho lze indexovat a dále s ním pracovat podobně, jako s jinými dokumenty na internetu.
Organizovaní, pořádání, popis a vyhledávání videa není nic nového, existovalo de facto ještě dříve, než se vůbec objevil internet či služby typu „video on demand“, tedy "video na přání". Existovaly totiž (off-line) archívy a knihovny, které se s existencí videa musely vypořádat již dávno před digitální revolucí. A internet nastolené postupy ochotně přebral.
Digitalizace do světa knihoven přinesla výzvu: jak přejít od popisu (a tedy i vyhledávání) formy, tj. například délka filmu, autor, postavy apod. k indexaci skutečného obsahu filmu, tedy rozpoznávání zvuků, obrazů, částí filmu apod.
Většina současných služeb vyhledávání videa stále staví spíše na formě, objevují se však i služby nové generace, které naznačují slibnou cestu skutečného pohledu do světa ozvučených obrázků.
Forma ve formě
Dva nejpoužívanější vyhledávače, Yahoo a Google, již dávno nabídly službu, která umožňuje prohledávat videa dostupná na internetu, tedy přesněji řečeno, ta videa dostupná v síti internet, která jsou za daných podmínek tyto dvě služby schopny indexovat.
Jinými slovy, zdaleka ne každý video produkt je pomocí těchto služeb nalezitelný, buď musí mít s provozovatelem služby nějakou vazbu (Google) a nebo musí být video obsah navázán na URL (Yahoo).
Obě služby těchto nesmiřitelných rivalů jsou si velmi podobné: umožňují prohledávat pomocí zadaného textového řetězce, nabízejí katalog videí roztříděný primárně podle žánrů, k vybranému videu přidávají základní informace o něm, související odkazy, rating, diskuzi a návštěvníkovi dále podstrkují nejvyhledávanější kousky.
Zatímco odkazy na videa od stejného autora (rozuměj zdroje) velmi nepravděpodobně pomohou uživateli, který hledá konkrétní téma, a spíše tak slouží k větší propagaci obsahu portálů, za náznak sofistikovanější pomoci uživateli lze považovat tagy, tedy jakási klíčová slova, která nabízí Yahoo.
Boj je však vyrovnaný, Google zase nabízí náhledy obrázků, jednotlivých sekvencí videa. Skromný test služby video.google.com a video.yahoo.com vykázal podobné výsledky vyhledávání, rychlost odezvy a přibližně stejný komfort služeb.
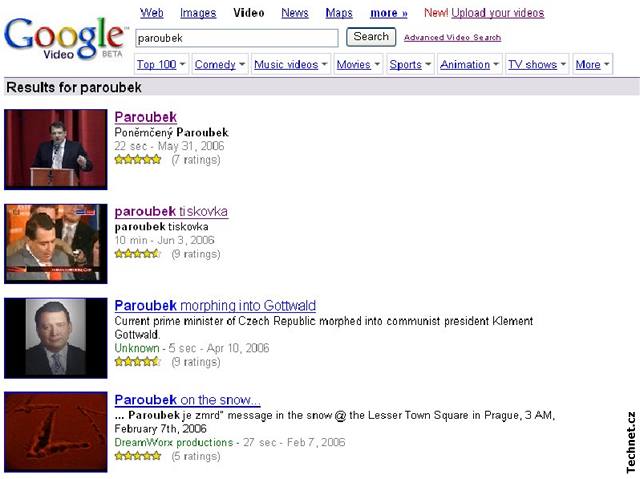

Microsoft nedávno též uvedl v život službu na prohledávání videa na internetu, ovšem jeho služba Windows Live Video Search (resp. testovací beta verze zmíněného produktu) nenabízí tak širokou škálu doprovodných (sekundárních a souvisejících) informací k vyhledanému materiálu, jakou má Google, Yahoo a nebo např. AOL, jehož služba video.aol.com nabízí video materiály podle žánrů, oblíbenosti a samozřejmě také produkci podporovaných společností a TV.
Jak proniknout do obsahu videa? Příklad z USA
Od roku 1998 je při Škole knihovnických a informačních služeb University Severní Karolíny v Chapel Hill rozvíjen projekt s názvem Open Video Project. Jeho dva hlavní tvůrci a představitelé, Gary Marchionini a Barbara M. Wildemuth, navštívili několikrát také Prahu, kde svoje pokroky v tvorbě uživatelsky přívětivých systémů pro vyhledávání obsahu na internetu představili odborné veřejnosti.
Videa, která v archivu Open Video projektu shromažďují, pochází a jsou určena pro výzkum, výuku, vzdělávání a jsou otevřena dalšímu zpracování.
Open Video Project
Projekt začínal se 195 kousky, dnes má Open Video Project asi 4 000 videí, některá velikosti a délky celovečerního filmu. Archiv se rozrostl především díky přispění několika velkých a významných kolekcí filmů určených ke vzdělávacím a osvětovým účelům, například edukační projekt NASA nebo Internet Archive, který obsahuje tisíce vzdělávacích filmů.
Zajímavý a jedinečný na této kolekci je fakt, že filmy v ní uložené pocházejí z let dávno před vznikem internetu, dokumentují kulturu, vědu, techniku a společnost let dávno minulých a digitalizovány byly teprve nedávno. Projekt je otevřený, tedy je možné video zadarmo stahovat, prohlížet, ale také dále používat.
Autoři projektu, odborníci na informační služby a knihovnictví, tímto projektem ukazují systematický a především velmi nadějný způsob nahlížení na organizaci, popis a vyhledávání video souborů.
Návštěvník stránky si všimne precizního popisu videí, který se zatím ničím výrazně neliší od popisu, jaký používá Google a nebo Yahoo. Snad až na zřejmější podporu odborníků na video a těch, kteří tento materiál chtějí dále použít, archiv m.j. poskytuje údaje o původcích, případných podmínkách pro další využití materiálu a copyrightu.
Mimochodem, materiál z Open Video Project podléhá licenci Creative Commons, což je výsledek hnutí, které směřuje k větší podpoře sdílení výsledků umělecké a vědecké činnosti. Pravidla jsou velmi jednoduchá: materiál takto licencovaný smíte stahovat, prohlížet, dále posílat, dokonce jej smíte měnit, tedy například jej použít pro své vlastní dílo, ovšem musíte: 1. uvést jméno původního autora díla, 2. nesmíte materiál použít ke komerčním účelům a 3. pokud materiál změníte a dále šíříte, opět jej musíte šířit se stejnými pravidly (tedy s licencí Creative Commons, zkráceně CC).
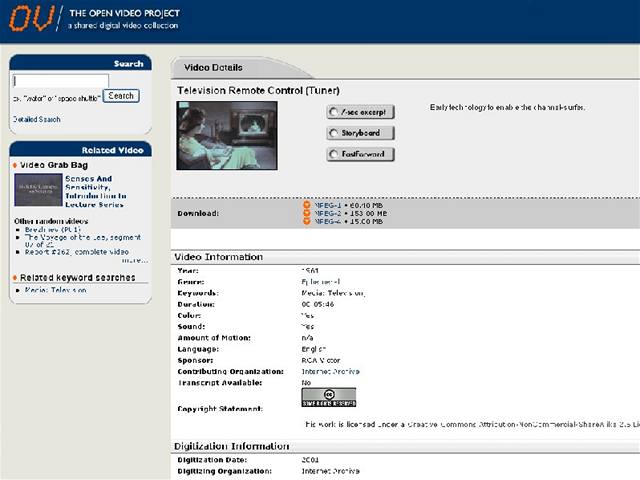
Co však již uživatel na první pohled nezaregistruje, je způsob, jakým je indexován obsah videí. Chceme-li zvýšit kvalitu vyhledávání textových informací, použijeme nejspíše takové nástroje, které nějakým způsobem „zhustí“ původní text do kratších útvarů, tedy například abstraktů nebo klíčových slov.
Vybírám-li si například knihu v obchodě a nebo hledám-li dokument na internetu, rozhodnu se pro nákup či stažení dokumentu na základě popisu, o čem kniha/dokument pojednává. Knihovníci ze Severní Karolíny uvažovali stejně i v případě audiovizuálních dokumentů, jenže jak „zhustit“ obsah videa? Testovali různé rychlosti procházení videa a zjistili, že stejně jako u rychločtení i u „rychlodívání“ se na video zachycujeme jenom určité obrázky, tedy jinými slovy, chceme-li se rychle seznámit s obsahem videa, stačí nám několik obrázků rozmístěných v pomyslném pásu filmu v určitém čase.
Autoři projektu Open Video Project tedy použili jakési „abstrakty“ z videa, které nejsou popisem obsahu jako například informace uváděné shodně na podobných portálech, ale jsou přímo jeho výtažkem.
Zjednodušený výstup z této práce vidí i návštěvník portálu: u videa jsou funkce rychlého přehrávání a náhledu snímku z videa.
Umíme se v Čechách také vypořádat s videem?
Příkladů sofistikovanější práce s video archivy bychom v USA našli mnoho, například při velkých univerzitách a jejich knihovnách existují řady digitalizačních projektů (např. Cornell University má několik desítek digitalizačních projektů, z nichž některé obsahují též videa – od návodných filmů pro výuku až po rozhovory a klipy).
Knihovna Kongresu také vytváří v této oblasti zajímavé archivy a v neposlední řadě to jsou významné výzkumné organizace, které po čase odhalují své archivy (např. NASA). Většina z nich má přidanou hodnotu především v tom, že 1. daleko precizněji popisuje obsah videa, podává tedy více sekundárních informací o obsahu, formě a původu videa, a 2. často se jedná o unikátní projekty digitalizace, jejichž výsledky odhalují kus dosud nepoznané historie, případně zpřístupňují dosud pouze archivní a tudíž těžko dostupné dokumenty.
Přínosný je také fakt, že materiály do takových archivů jsou vybírány systematicky a tudíž od nich očekáváme daleko vyšší kvalitu než od nahodilých sbírek toho, co bylo možné zindexovat. Nezanedbatelným plusem je také skutečnost, že často jsou materiály zcela volně k dispozici za jasných podmínek, které zpravidla umožňují nezávislou tvorbu a vzdělávání.
U nás byl v roce 2003 zahájen projekt založený na spolupráci CESNETu, Ústavu informačních studií a knihovnictví FF UK a firmy Jyxo. Projekt se nejdříve zaměřil pouze na multimediální obsah serverů v doméně .cz.
Zařízení se skládá z crawleru, který prochází web a vyhledává multimediální soubory, destilleru, který importuje adresy, získává metadata a vytváří náhledy, a databáze, která v současné době pokrývá v několika desítkách vrcholových domén přes 3 miliony adres, z toho 2 miliony validních a 600 000 s náhledy.
Další vývoj projektu se zaměří na vrcholové domény mimo .cz, především pak v EU a na podporu dalších jazyků, detekci duplicit a implementaci knihovnického přístupu ve spolupráci s vydavateli obsahu pomocí metod OAI (Open Archive Initiative).
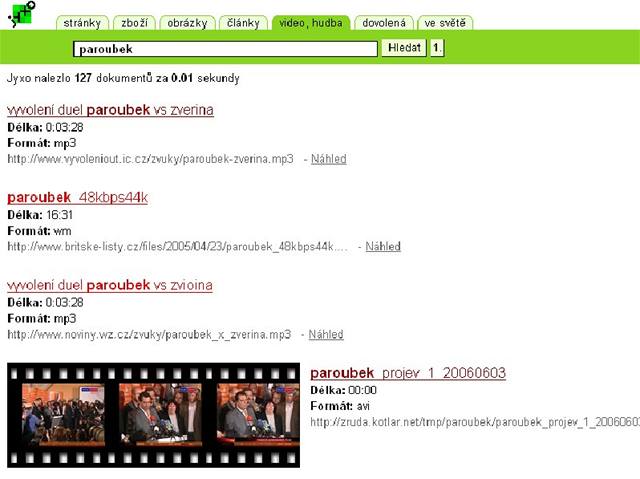
Projekt je možné vyzkoušet na adrese ZDE, více o projektu i o přístupech k vyhledávání multimediálních souborů obecně se dočtete ZDE.
Autorka je redaktorkou časopisu Ikaros.



{kind=link}